We would like to thank MuleSoft Ambassador Joshua Erney for their contribution to this developer tutorial.
In this tutorial, you’ll learn some examples to remove duplicate items or retrieve unique items from an Array using the distinctBy function. If you come from a database background, you may know this function as DISTINCT. We’ll learn how to write the prefix and infix notations, as well as the use of an explicit lambda and the dollar-sign syntax.
You can try all of these examples with the DataWeave Playground. To learn more about it, check out this tutorial.
Prerequisites
While not required to follow this tutorial, a good understanding of the basic DataWeave concepts would be preferred. You can check out these other tutorials if you feel a bit lost with some concepts:
- What is DataWeave? Part 1 - To understand MIME types, the script anatomy, and data types.
- What is DataWeave? Part 2 - To understand how to use the selectors to retrieve data.
- What is DataWeave? Part 3 - To understand variables, boolean operators, flow control, and named functions (prefix and infix notations).
- What is DataWeave? Part 4 - To understand what are lambdas (anonymous functions), higher-order functions, infix notation, and the dollar-sign syntax.
- What is DataWeave? Part 5 - To understand what is the syntax of the type parameters (or generics).
Syntax
The distinctBy function is useful when you need to remove duplicate items from an Array. It takes two parameters: an Array and a lambda. The lambda passed to distinctBy should return a value that is unique to each item in the input Array.
distinctBy(Array<T>, ((T, Number) -> Any)): Array<T>Prefix Notation
This function is not commonly used with the prefix notation because of its complexity. But here you can find an example that removes the duplicate numbers from the input Array.

Infix Notation
This is the most used notation for this function because it makes it easier to read and understand.

When using the infix notation, you don’t have to include all the parameters in the lambda if you’re not using them. However, you do have to include the previous parameters (to the left) whether you’re using them or not. You can only remove the parameters to the right.
In this case, since num is the first parameter, we can also use the following code:
1
2
3
4
%dw 2.0
output application/json
---
[1, 2, 2, 3, 4, 2, 1] distinctBy ((num) -> num)
Dollar-sign Syntax
You don’t always need to include the whole explicit lambda expression as the second argument. You can use the dollar-sign syntax to reference the two arguments that are passed to the lambda (i.e., num and numIndex). $ represents the value of the item (num), while $$ represents the index (numIndex).

Remove Duplicate Objects by Field
A typical use case would be to remove duplicate Objects in an Array based on a unique field. In this example, we have an Array of Objects (Array<Object>) with the fields id and environment. We want to remove the duplicate objects based on the unique id field.
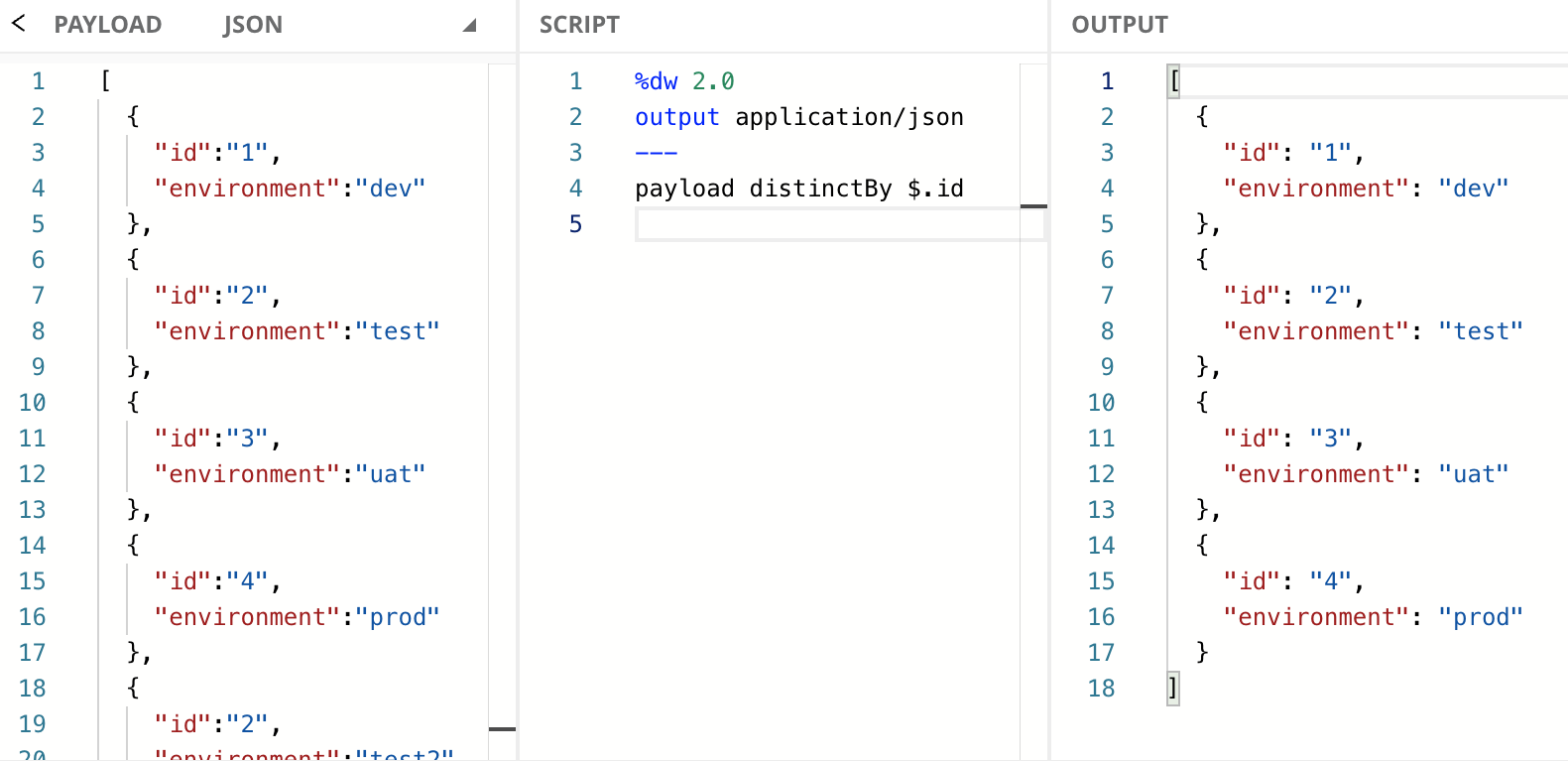
We used the infix notation and the dollar-sign syntax because the code looks cleaner than the prefix notation and/or the explicit lambda. If you wanted to use explicit lambda, while still using the infix notation, the same code would look like this:
1
2
3
4
%dw 2.0
output application/json
---
payload distinctBy ((env) -> env.id)
Remove Duplicate Objects by Multiple Fields
You might also need to combine multiple values in an Object to determine uniqueness. To do that, you can turn them into Strings and concatenate them with ++ to create a unique value. In this example, we have an Array of Objects (Array<Object>) with the fields orderId, lineId, and product. We want to remove the duplicate objects based on the combination of orderId and lineId fields.
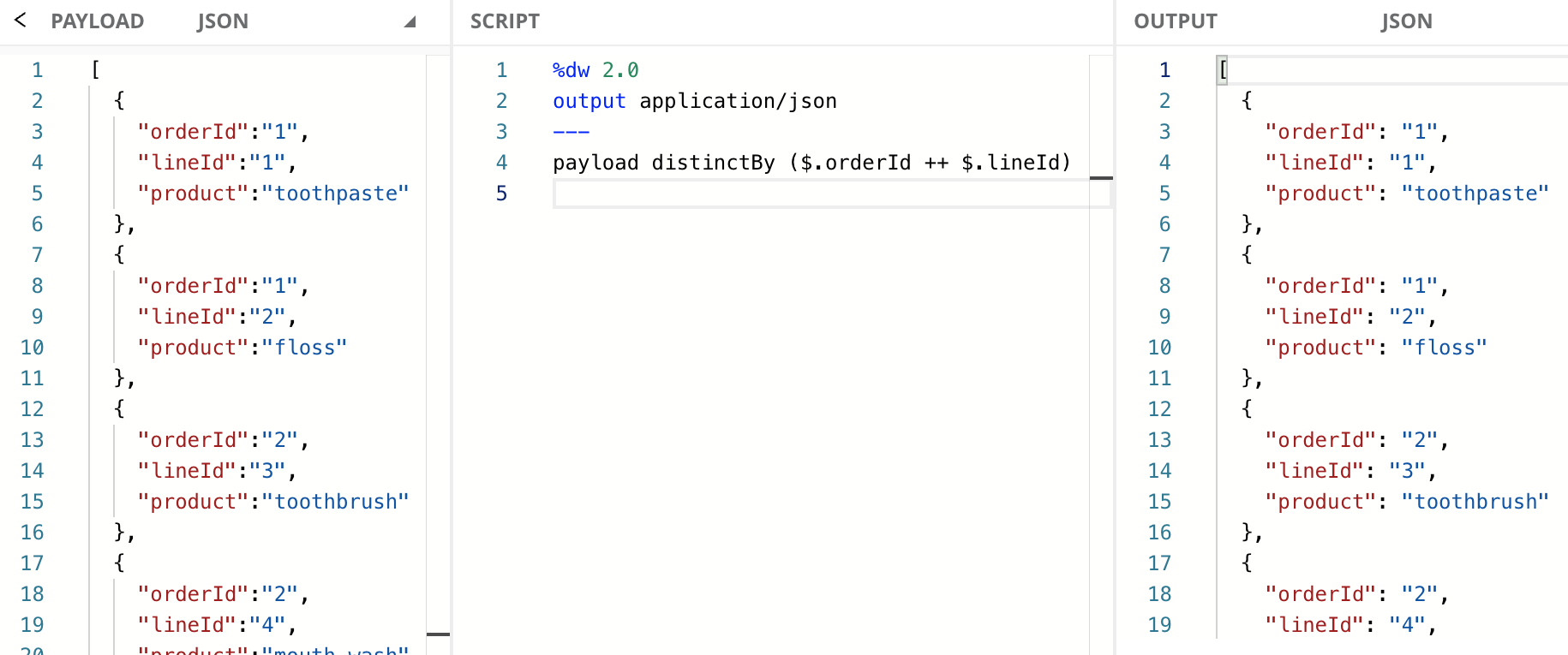
If you’re not familiar with the ++ function, it can be used with two Strings to concatenate them into a new String. All the different ways to use ++ are out of scope for this tutorial, but you can learn more about it in the documentation or this developer tutorial.
In this example, we also used the infix notation and the dollar-sign syntax because the code looks cleaner. If you wanted to use explicit lambda, while still using the infix notation, the same code would look like this:
1
2
3
4
%dw 2.0
output application/json
---
payload distinctBy ((item) -> item.orderId ++ item.lineId)
Add Characters to Multiple Field Concatenation
A problem with the previous example’s solution is that the values are just being concatenated - they’re not bound to the fields they come from. This becomes a problem when the concatenated value from one Object is the same value from a second Object. While the probability of this happening in a real-life scenario is very low, it’s not impossible. In the next example, we have an Array of Objects with the fields id1, id2, and name. We want to remove the duplicate Objects by the combination of the id1 and id2 fields. If you take a look at the input payload, you will notice that only test1 and test4 are duplicates. However, let’s take a look at the script and the output.
We will use the same input payload for the rest of the demonstrations in this section.
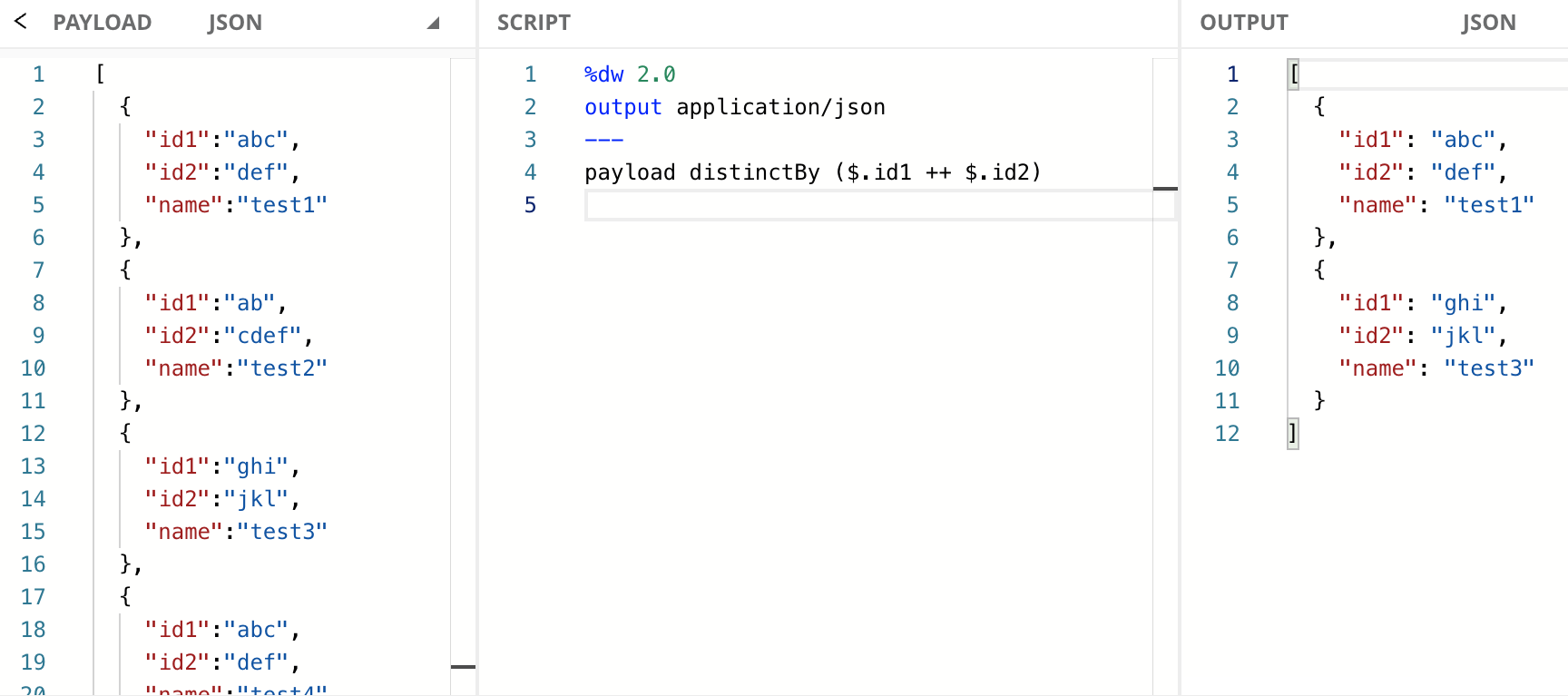
As you can see, test4 was correctly removed, but also test2 even though it was not a duplicate. Why did this happen? Because we are sending a concatenation of id1 and id2. When we concatenate these fields from the first Object, we receive a value of "abcdef", which is the same value we receive for the second and last Objects. Because of this, DataWeave thinks we’re talking about duplicate Objects. Here you can see the demonstration of what’s happening internally with the concatenation:
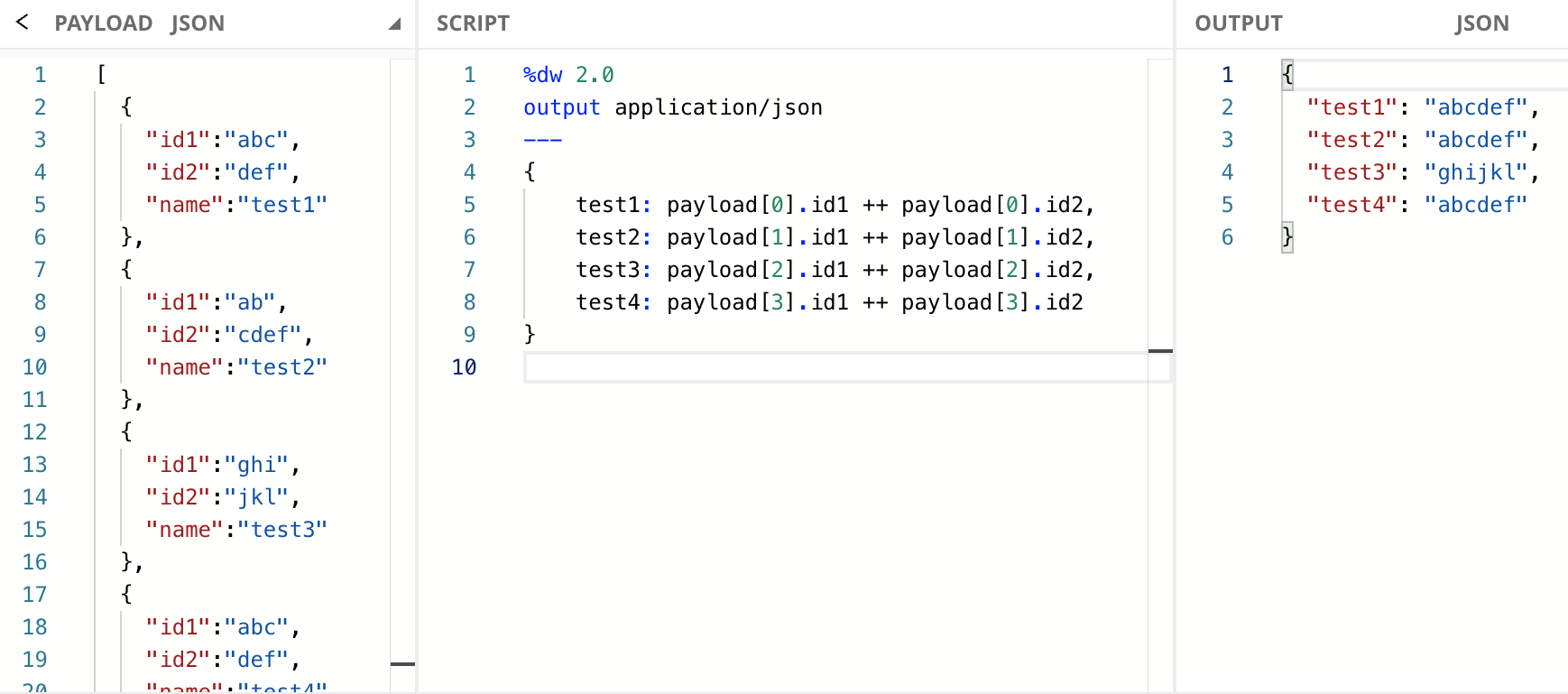
To learn more about the Index Selector ([0]), check out the documentation or this developer tutorial.
How can we fix this issue? By adding a separator, or a prefix and suffix to the fields so they can be unique. For example, instead of having "abcdef" in the first Object, we could add a separator like a comma ("abc,def").
1
2
3
4
%dw 2.0
output application/json
---
payload distinctBy ($.id1 ++ "," ++ $.id2)
If we wanted to be extra sure that the fields would not repeat, we could also add a prefix and a suffix to the String. For example, "[abc,def]".
1
2
3
4
%dw 2.0
output application/json
---
payload distinctBy ("[" ++ $.id1 ++ "," ++ $.id2 ++ "]")
But what will happen when we have more than 2 fields that we want to use? This concatenation will just become bigger and bigger if we keep using the ++ function. Another way to achieve this is with the joinBy function. We can send an Array of Strings (Array<String>) with our values and select the character we want to use as a separator.
Separate values by comma
1
2
3
4
%dw 2.0
output application/json
---
payload distinctBy ([$.id1, $.id2] joinBy ",")
Add prefix/suffix
1
2
3
4
5
6
7
8
%dw 2.0
output application/json
---
payload distinctBy (
"[" ++
([$.id1, $.id2] joinBy ",")
++ "]"
)
If you’re not familiar with the joinBy function, it can be used with an Array of Strings (Array<String>) and a String to concatenate the Strings from the Array into a new String with the given separator character/String. All the different ways to use joinBy are out of scope for this tutorial, but you can learn more about it in the documentation.
Finally, to improve the readability of the code we can include a named function to pass the concatenated values to the distinctBy function.
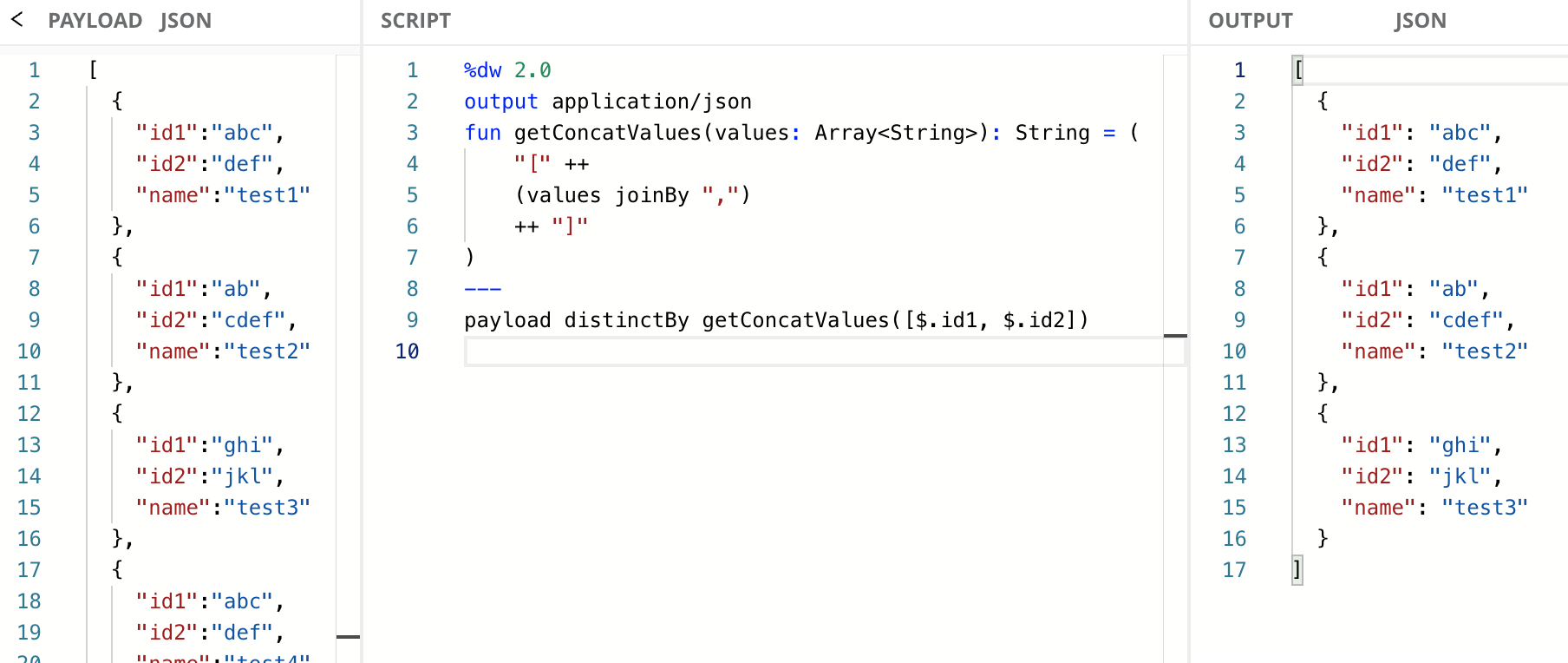
If you want to see the values that are sent to the distinctBy function, you can either use the log function to see them in the console (i.e., distinctBy log($.id1)) or temporarily swap the distinctBy function with map (i.e., payload map ($.id1)).
To learn more about log, check out the documentation.
To learn more about map, check out the documentation or this developer tutorial.
Next Steps
In this tutorial, you learned some examples to remove duplicate items from an Array using the distinctBy function. You saw simpler examples like using Array<Number> and more complex examples with Array<Object>. You learned how to remove duplicate Objects with a single field or with a combination of multiple fields by concatenating the values.
Continue your development journey with the rest of the tutorials to become a master in DataWeave.


Try Anypoint Platform for free
Start your 30-day free trial of the #1 platform for integration, APIs, and automation. No credit card required. No software to install.
Questions? Ask an expert.