We would like to thank MuleSoft Ambassador Joshua Erney for their contribution to this developer tutorial.
In this tutorial, we will see an overview of how DataWeave works and the very basics of the language. You’ll learn more about:
- MIME types used to transform the data
- The anatomy of a DataWeave script
- DataWeave’s data types
If this is your first time learning about DataWeave, we encourage you to check out this other tutorial to learn about the online DataWeave Playground. With this tool, you will be able to try out the scripts you will see in this tutorial right from your browser.
What is DataWeave?
DataWeave is a functional programming language designed for transforming data. It is MuleSoft’s primary language for data transformation, as well as the expression language used to configure components and connectors. However, DataWeave is also available in other contexts, like as a command-line tool. These tutorials will largely treat DataWeave as a standalone language, with Mule-specific info designated with (M).
DataWeave allows users to easily perform a common use case for integration developers: read and parse data from one format, transform it, and write it out as a different format. For example, a DataWeave script could take in a simple CSV file and transform it into an array of complex JSON objects. It could take in XML and write the data out to a flat file format. DataWeave allows the developer to focus on the transformation logic instead of worrying about the specifics of reading, parsing, and writing specific data formats in a performant way.

When DataWeave receives data, it puts it through the reader. The reader’s job is to parse the input data into a canonical model. It then passes that model to the DataWeave script where it is used to generate the output, which is another canonical model. That last canonical model is passed into a writer. The writer is responsible for serializing the canonical model into the desired output data format.
MIME Types
While DataWeave can handle itself when it comes to parsing and serializing data, it does need to be told what data to expect. This is done by specifying MIME types for the inputs and output. MIME types specify the data format of a particular document, file, or piece of data. We use them to inform DataWeave what data format to read and write. There are many MIME types, but DataWeave only uses a subset of them that make sense for its data transformation domain. Of that subset, there are only 3 we will concern ourselves with for this tutorial:
application/xml- XMLapplication/json- JSONapplication/csv- CSV
Here’s an example that takes in an array of JSON objects and transforms it into a CSV without a header.
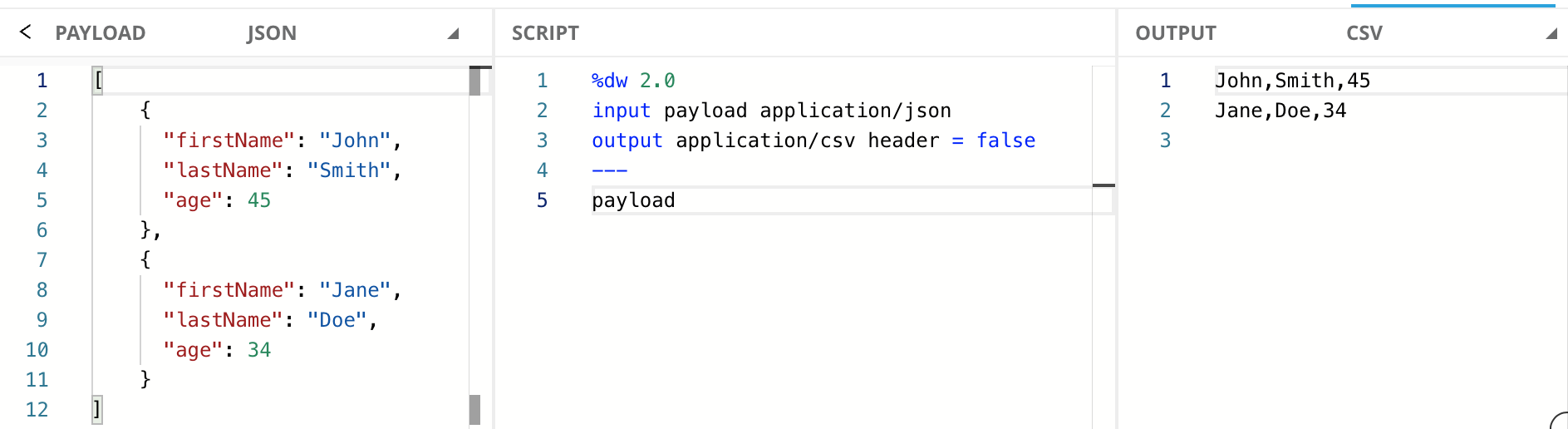
This tutorial series will use an output MIME type of application/json for most cases. Other MIME types will be used to shed light on certain language features that may seem odd or not very useable otherwise. It will review more specific considerations for other MIME types later in the tutorial.
Script Anatomy
Let’s go over the anatomy of a DataWeave script using the code from the last example:
1
2
3
4
5
%dw 2.0
input payload application/json
output application/csv header=false
---
payload
The first three lines of the script contain directives. The first directive, which is in every DataWeave file, defines which version the script is using. You can think of this more as a necessary formality, as other factors will determine which DataWeave version is used to run your script (e.g., the Mule Runtime).
(M) If you’re in a Mule 3 project, you will always use %dw 1.0. If you’re in a Mule 4 project, you will always use %dw 2.0.
The second and third lines contain the input and output directives. They each have their own form:
input <var_name> <mime_type> [<reader_properties>]
output <mime_type> [<writer_properties>](M) If you’re in a Mule 4 project, you won’t be using the input directive at all. Instead, set the MIME type and any reader properties on your message source (e.g., HTTP Listener).
After the first three lines of the script, there is a line only containing three dashes. This is to separate your declarations from your script output logic. You’ll see in later tutorials that you can do more than just specify input and output directives in the declarations section, you can also declare functions and variables that you can reuse in your script.
The last line of the script is the output section. In Mule projects, payload refers to a predefined variable that corresponds to the payload of the Mule Event as it hits a DataWeave script. Whatever the output section evaluates to, is what gets sent to the writer and is ultimately serialized into the specified output format.
Data Types
This section will focus on how you can create data with DataWeave and the different data types the language supports.
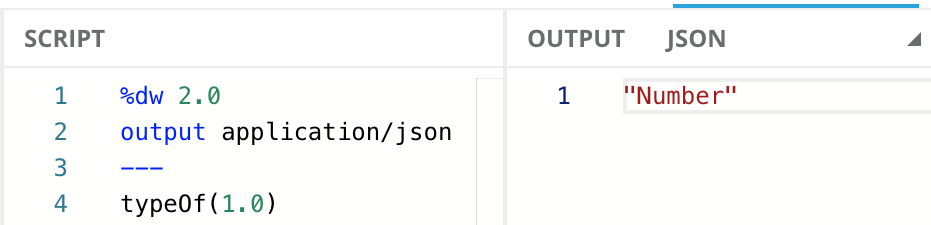
You can check the type of a value by using the function typeOf.
String
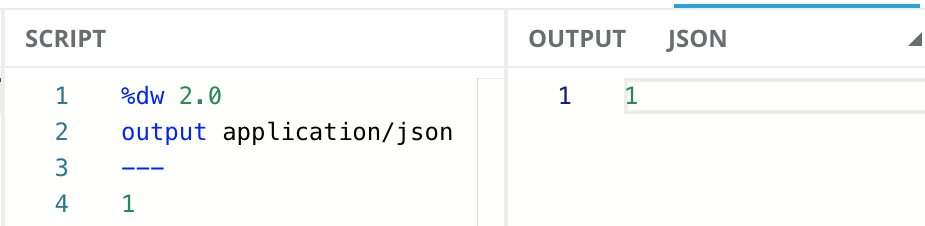
Like most programming languages, DataWeave does not need input data to generate output. For example, the following script takes no input, it just outputs the String "Hello".

Number
DataWeave also supports numbers with the Number type. The Number type supports both integer and floating-point numbers.
Boolean
The last simple type we’ll cover in this tutorial is the Boolean type. The Boolean type only has two values: true and false. Booleans are valuable when it comes to conditional logic (e.g., if something is true, do this, if it’s false, do this instead) which we will cover in the next section.
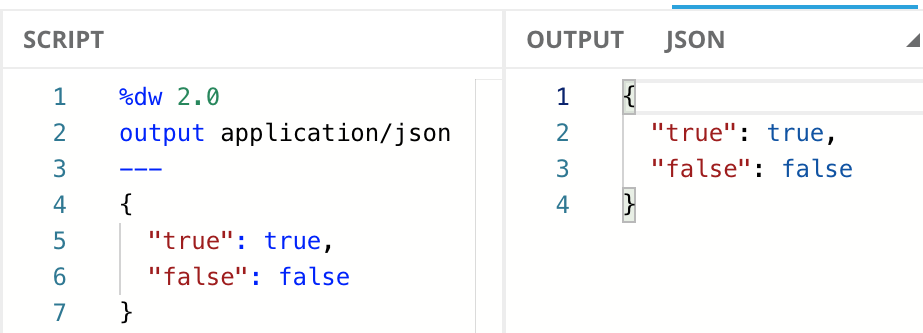
Array
In addition to Strings, Numbers, and Booleans, DataWeave also supports collections with Arrays and Objects. Arrays are an ordered series of values where the values can be of any type.
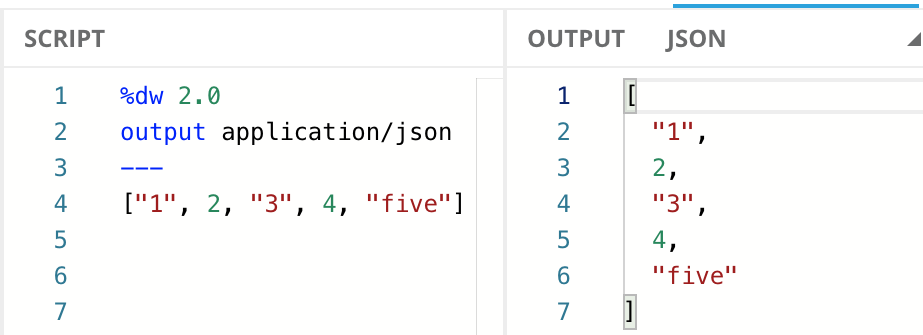
Object
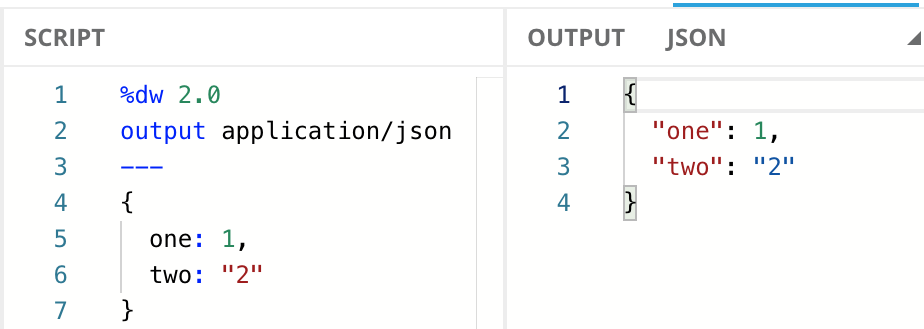
Objects are a series of key-value mappings, where the value can be of any type.
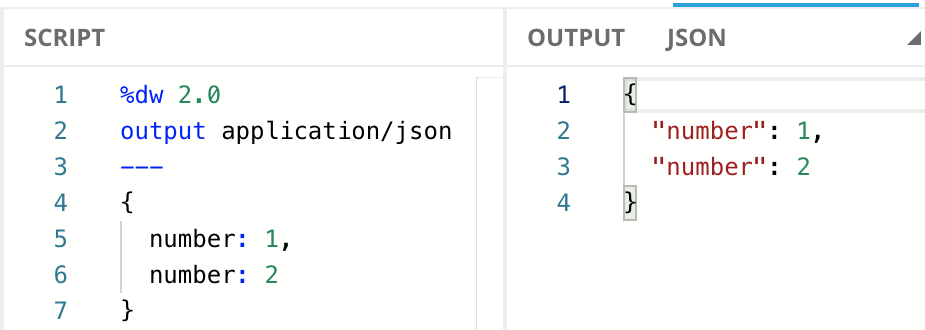
DataWeave allows repeated keys on Objects as well.
Next Steps
This tutorial only covered the very basics of what’s possible in DataWeave. You learned about:
- MIME types used to transform the data
- The anatomy of a DataWeave script
- DataWeave’s data types to create data
In the next tutorial, we’ll learn about selectors to read data coming from the input payload or other variables.
Click on the Next button below to continue to the next tutorial.


Try Anypoint Platform for free
Start your 30-day free trial of the #1 platform for integration, APIs, and automation. No credit card required. No software to install.
Questions? Ask an expert.