Overview
MuleSoft helps developers execute a variety of integration use cases from within the AWS ecosystem. One of the most common use cases we see is connecting AWS services out of the AWS ecosystem to external systems in a reusable, accelerated manner. In this developer tutorial, we are going to walk through how to synchronize data between Amazon S3 and Salesforce using MuleSoft’s Anypoint Platform. This is just one example of how MuleSoft provides out-of-the-box connectivity to AWS services such as S3, DynamoDB, SQS, and to common external systems like Salesforce, SAP, Oracle, etc.
Developers can use MuleSoft to interface with Amazon S3 to store objects, download files, use data with other AWS services, and to build applications that require internet storage. Amazon S3 easily integrates with MuleSoft when using the Amazon S3 Connector, which you can drag and drop into your Anypoint Studio project.
With Amazon S3, you can execute a few common business operations such as:
- Build apps with native cloud-based storage: Connect your application to scalable Amazon S3 buckets to store files, images, and other files.
- Backup and archive critical data: Use the Amazon S3 connector to seamlessly integrate with your ERP, CRM (such as Salesforce), EDI, and fulfillment systems, and archive necessary data.
- Drive business intelligence and optimize operational outcomes: Leverage Amazon S3 as a storage repository that holds a vast amount of raw data in its native format until as needed. Use your data lake to extract valuable insights on your data such as machine learning, analytics, and query data assets without having to provision or manage clusters.
In the steps that follow, we are going to walk through how to set up your Amazon S3 connector with MuleSoft’s Anypoint Studio. You will need to have an Amazon AWS account in order to get started and will need to grab your security credentials from the Amazon AWS console.
To download the assets used in the project, feel free to download the jar file located here and import it into your Anypoint Studio project. To import go to File -> Import -> Packaged Mule application (JAR)
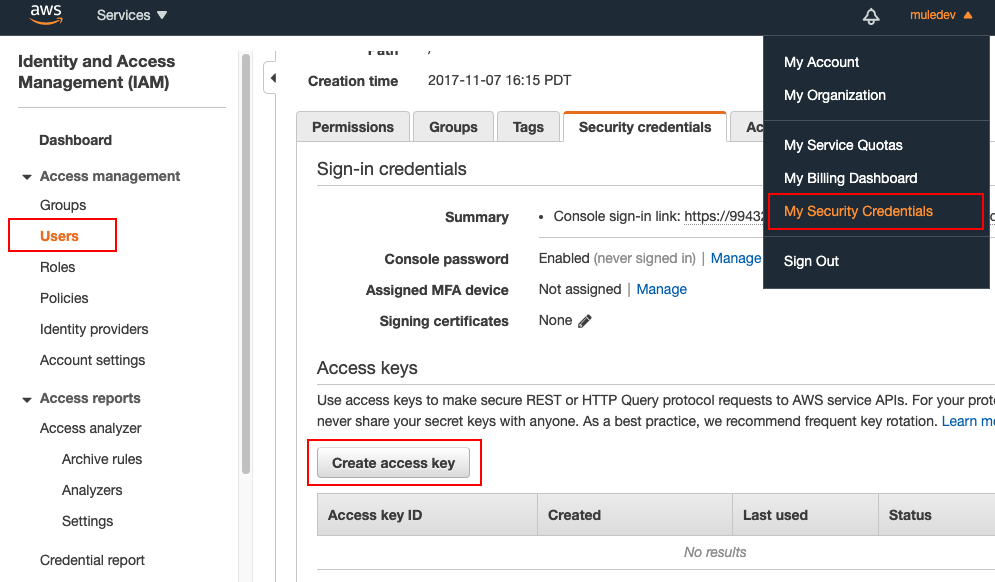
Step 1: Obtain security credentials from Amazon AWS
First login to your Amazon AWS account and go to the top right corner and select My Security Credentials. Then click on Users on the sidebar, and click the button Create access key. You will need to copy your access key credentials into your local.properties file in your Anypoint Studio project.
If you haven’t already, make sure to sign up for a free Anypoint Platform account. Click the button below to create a free account.
Already have an account? Sign in.
Step 2: Set up your project
In this integration, we will be using the Salesforce Connector to backup new object data to our Amazon S3 Bucket.
Every time a new object is an input into Salesforce, this entire flow will execute.

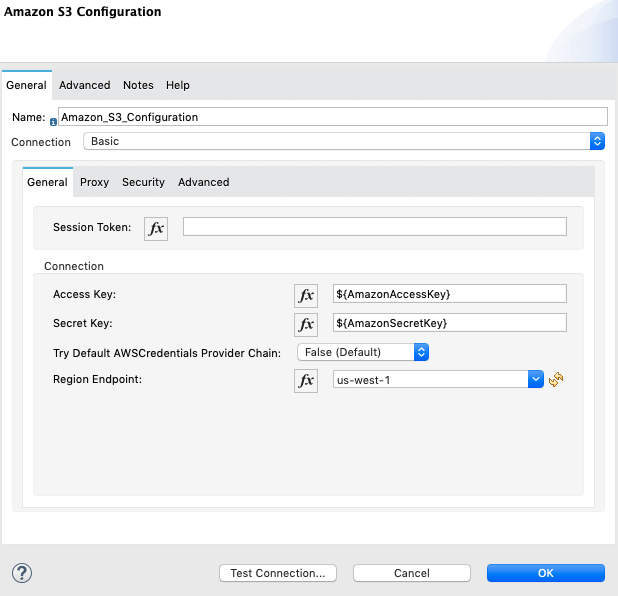
In order to set up your Amazon S3 Connector, you will need to create a configuration properties file and add your AWS access key and secret key to it. We also have added fields for your Salesforce Username, Password, and the optional Security Token as well.
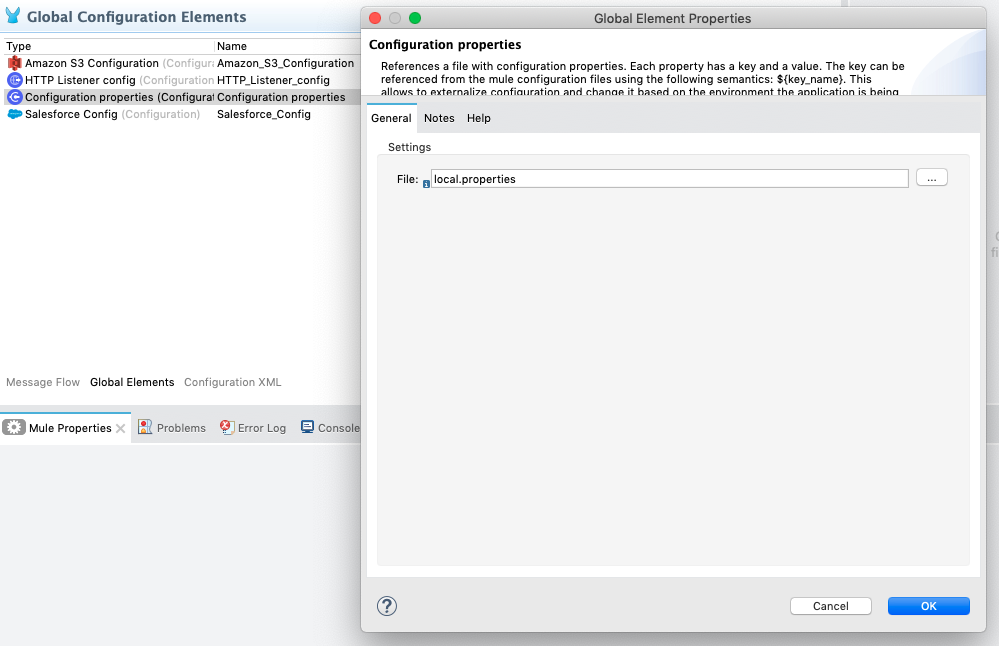
Create your local.properties file, go to File -> New -> File, and name the file local.properties and place it in your src/main/resources folder.
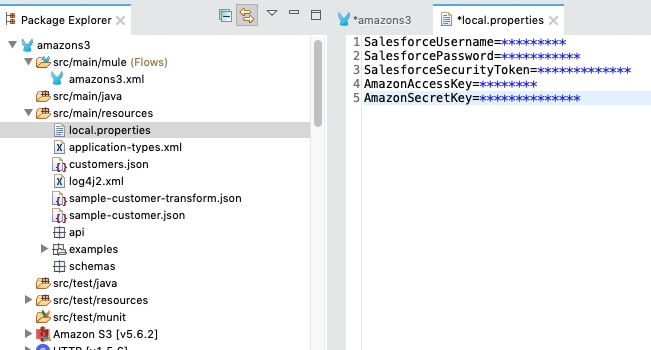
Then under your Global Configuration Elements menu, create a new Configuration Properties file and assign the local.properties file to the configuration properties element.
The Amazon S3 Connector offers over 50 operations as shown below for you to explorer and develop rich use cases for. For more documentation on how to add the Connector to your project and add the connector to Studio, read the documentation here.

Step 3: Developing the integration between S3 and Salesforce
In the video below, you will see that our flow is made up of a few different components. The first component is the Salesforce Connector that is listening for a New Object to be created in your Salesforce instance. For this demo, we selected Lead as the Object Type. Whenever a new Lead is added to Salesforce, this entire flow will execute. It’s important to change the Frequency on the Salesforce Connector to the time value that works for your use case. For this tutorial, we have the Salesforce Connector polling every 10 seconds.
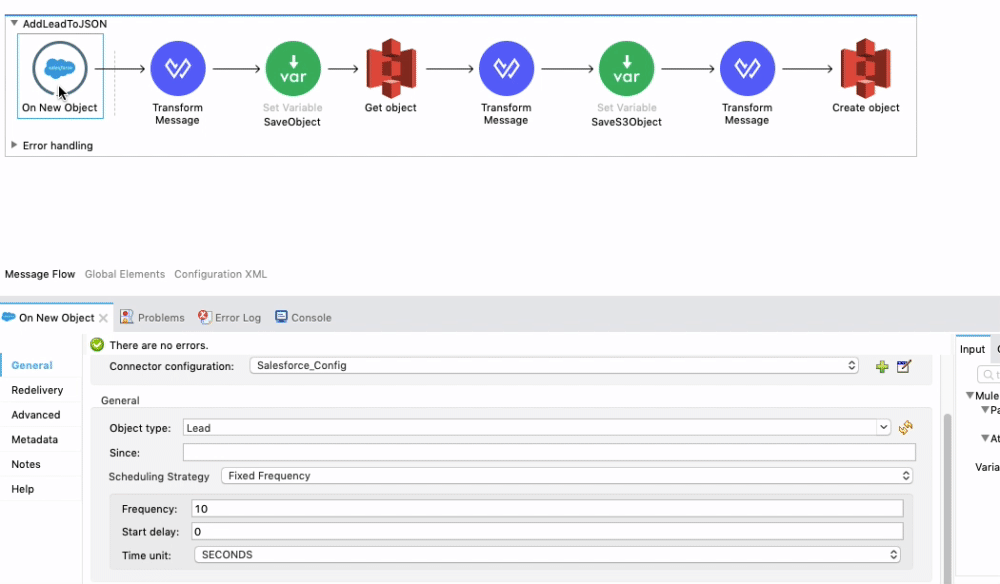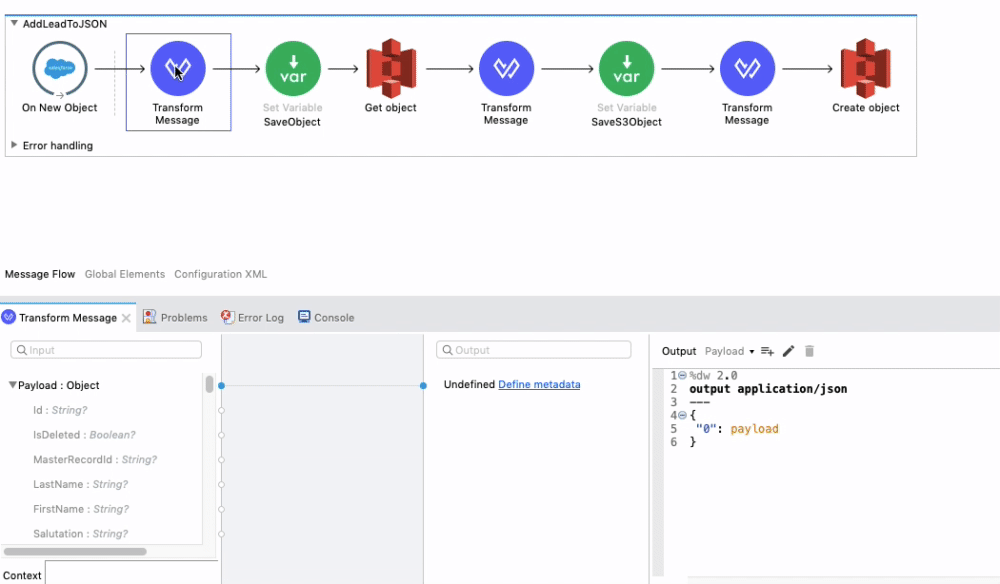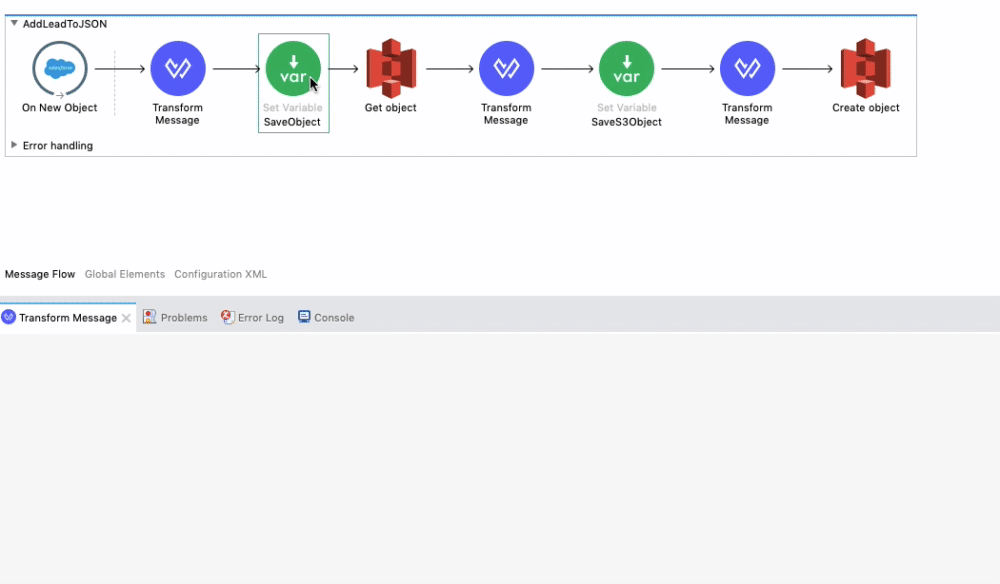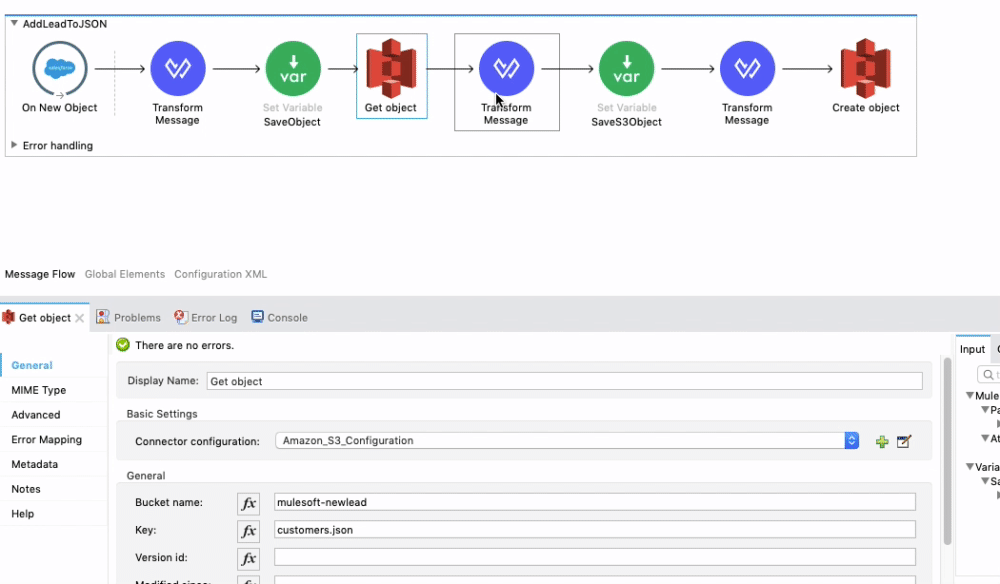
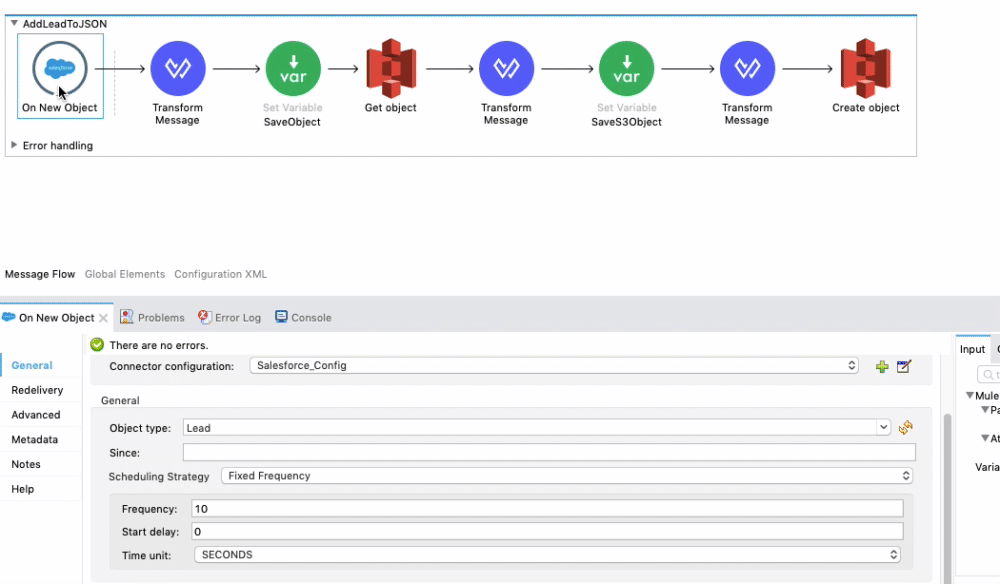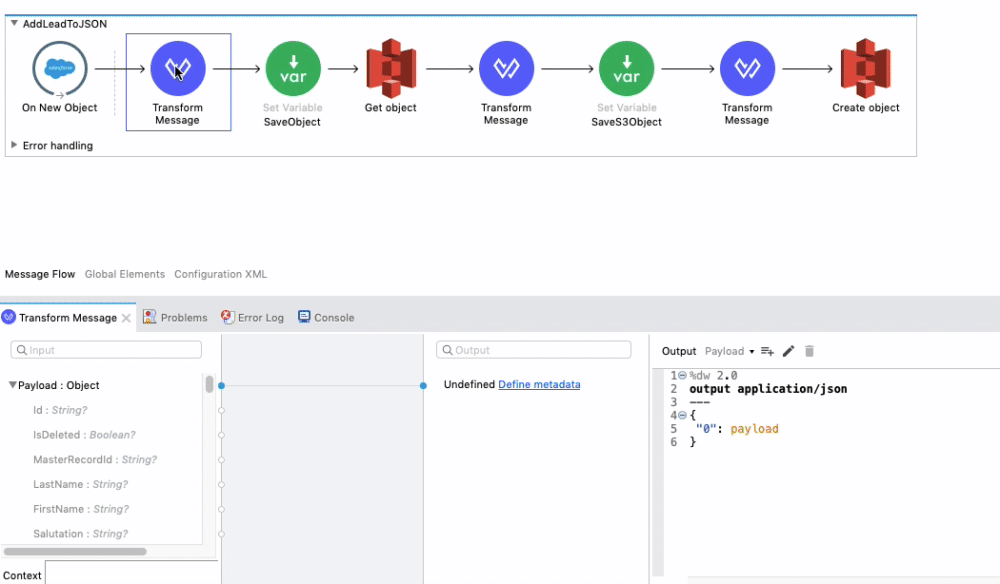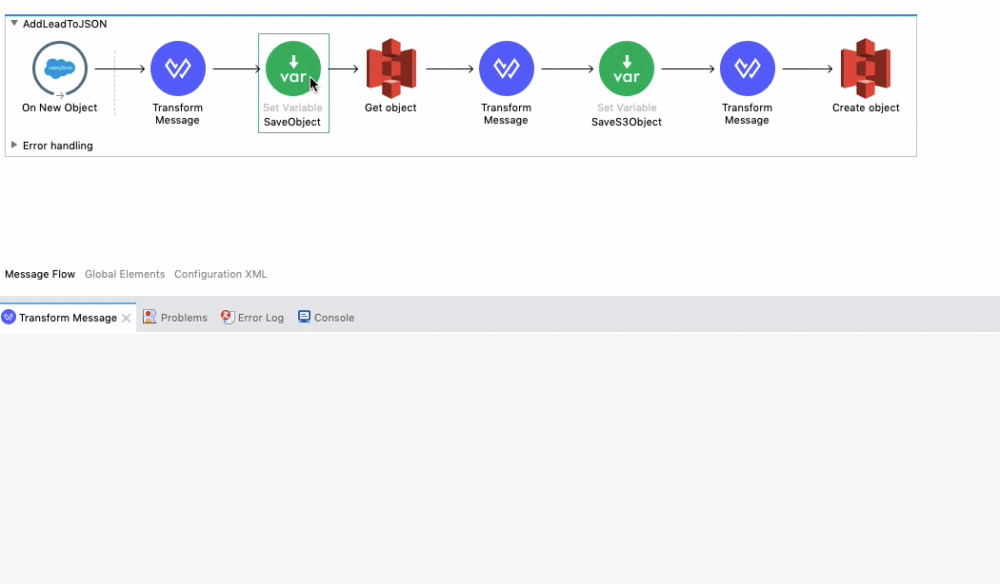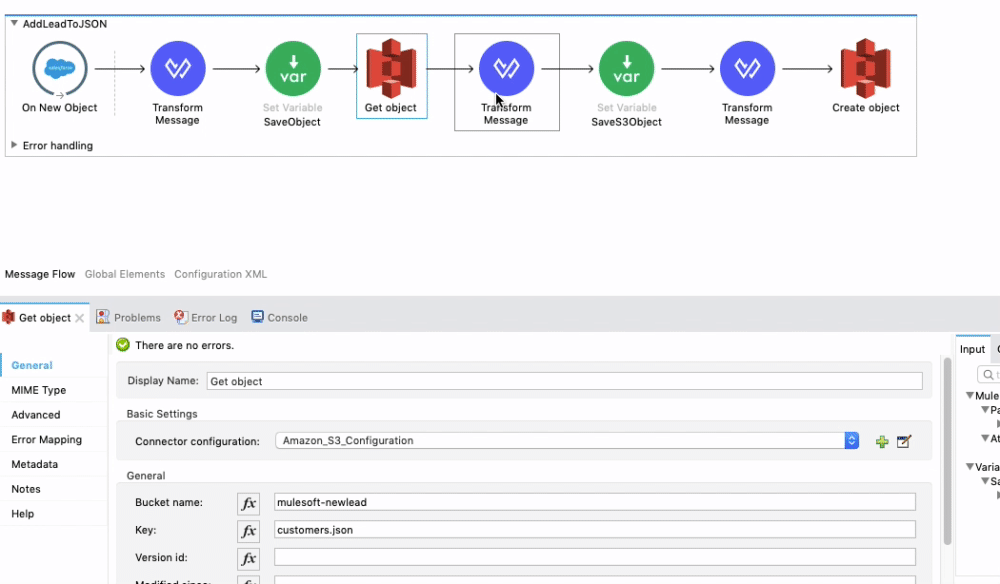
The next component is the Transform Message Connector. We use a Dataweave script to format the payload in a format that is similar to the one found on our S3 bucket.
1
2
3
4
5
6
%dw 2.0
output application/json
---
{
"0": payload
}
This is how the Payload will look from Salesforce once we transform it using Dataweave:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
{
"0" :
{
"LastModifiedDate": "2020-10-21T21:55:38.000Z",
"Company": "MuleSoft",
"Email": null,
"Address": null,
"Latitude": null,
"ProductInterest__c": null,
"type": "Lead",
"MobilePhone": "4084895392",
"Name": "Jordan Schuetz",
"Industry": null,
"CreatedById": "0051U000005VuIMQA0",
"SICCode__c": null,
"Street": null,
"DandbCompanyId": null,
"PhotoUrl": "/services/images/photo/00Q1U00000PDqYvUAL",
"ConvertedOpportunityId": null,
"MasterRecordId": null,
"IndividualId": null,
"Status": "Open - Not Contacted",
"IsDeleted": "false",
"ConvertedAccountId": null,
"IsConverted": "false",
"LastViewedDate": "2020-10-21T21:55:38.000Z",
"City": null,
"Longitude": null,
"CleanStatus": "Pending",
"LeadSource": null,
"GeocodeAccuracy": null,
"Primary__c": null,
"State": null,
"CreatedDate": "2020-10-21T21:55:38.000Z",
"Country": null,
"Id": "00Q1U00000PDqYvUAL",
"LastName": "Schuetz",
"AnnualRevenue": null,
"Jigsaw": null,
"EmailBouncedDate": null,
"Description": null,
"ConvertedDate": null,
"Rating": null,
"PostalCode": null,
"Website": null,
"LastReferencedDate": "2020-10-21T21:55:38.000Z",
"NumberOfEmployees": null,
"CompanyDunsNumber": null,
"Salutation": null,
"ConvertedContactId": null,
"OwnerId": "0051U000005VuIMQA0",
"Phone": null,
"NumberofLocations__c": null,
"EmailBouncedReason": null,
"FirstName": "Jordan",
"IsUnreadByOwner": "false",
"Title": null,
"SystemModstamp": "2020-10-21T21:55:38.000Z",
"CurrentGenerators__c": null,
"LastActivityDate": null,
"Fax": null,
"LastModifiedById": "0051U000005VuIMQA0",
"JigsawContactId": null
}
}
We then save the Payload as the variable SaveObject so we can reference it later in the flow and append it to the existing document on S3.
Next, we grab the most recent object from our S3 bucket! Simply enter the Bucket Name in the Get Object General settings, and under Key, type in the name of your file which in this case is customers.json. You can download the customers.json file by clicking the button below.
We then use another Transform Message component to append the most recent object from Salesforce to the current customers.json file located on S3. Then we take that new file, and reupload it to S3 replacing the old file on the server.
1
2
3
4
5
6
7
8
9
10
%dw 2.0
output application/json
---
vars.SaveS3Object mapObject ((value, key, index) ->
{
(index) : value,
}) ++ vars.SaveObject mapObject ((value, key, index) ->
{
(index) : value,
})
If you get the error: Message: “You called the function ‘mapObject’ with these arguments: 1: String, 2: Function but expected But it expects arguments of these types: 1: Object 2: Function”, make sure that you are changing your DataWeave code to read the file as JSON. To fix the issue, add the script to your Transform component after the S3 Get Object Connector:
1
2
3
4
%dw 2.0
output application/json
---
read(payload,'application/json')
As you can see in the script below, you can see that the Dataweave script added an index to the next value and will keep adding values to this JSON file for every new Lead added on Salesforce.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
{
"0": {
"LastModifiedDate": "2020-10-21T21:55:38.000Z",
"Company": "MuleSoft",
"Email": null,
"Address": null,
"Latitude": null,
"ProductInterest__c": null,
"type": "Lead",
"MobilePhone": "4084895392",
"Name": "Jordan Schuetz",
"Industry": null,
"CreatedById": "0051U000005VuIMQA0",
"SICCode__c": null,
"Street": null,
"DandbCompanyId": null,
"PhotoUrl": "/services/images/photo/00Q1U00000PDqYvUAL",
"ConvertedOpportunityId": null,
"MasterRecordId": null,
"IndividualId": null,
"Status": "Open - Not Contacted",
"IsDeleted": "false",
"ConvertedAccountId": null,
"IsConverted": "false",
"LastViewedDate": "2020-10-21T21:55:38.000Z",
"City": null,
"Longitude": null,
"CleanStatus": "Pending",
"LeadSource": null,
"GeocodeAccuracy": null,
"Primary__c": null,
"State": null,
"CreatedDate": "2020-10-21T21:55:38.000Z",
"Country": null,
"Id": "00Q1U00000PDqYvUAL",
"LastName": "Schuetz",
"AnnualRevenue": null,
"Jigsaw": null,
"EmailBouncedDate": null,
"Description": null,
"ConvertedDate": null,
"Rating": null,
"PostalCode": null,
"Website": null,
"LastReferencedDate": "2020-10-21T21:55:38.000Z",
"NumberOfEmployees": null,
"CompanyDunsNumber": null,
"Salutation": null,
"ConvertedContactId": null,
"OwnerId": "0051U000005VuIMQA0",
"Phone": null,
"NumberofLocations__c": null,
"EmailBouncedReason": null,
"FirstName": "Jordan",
"IsUnreadByOwner": "false",
"Title": null,
"SystemModstamp": "2020-10-21T21:55:38.000Z",
"CurrentGenerators__c": null,
"LastActivityDate": null,
"Fax": null,
"LastModifiedById": "0051U000005VuIMQA0",
"JigsawContactId": null
},
"1": {
"Discovery_Prescription__c": "+48.106 if you change Trade Show Invite to true\n+19.006 if you change Marketing Promo to Spring Early Bird Promo\n+10.849 if you change Marketing Promo to Mid-Season Special\n+6.579 if you change Marketing Promo to CA Solar Energy Convention Promo\n+5.515 if you change Marketing Promo to Renewable Installation Promo\n+2.298 if you change Marketing Promo to Memorial Day",
"LastModifiedDate": "2020-10-27T16:51:01.000Z",
"Trade_Show_Invite__c": "false",
"partdir_mp__AC_Partner_Account_Id__c": null,
"Address": null,
"HasOptedOutOfFax": "false",
"Score4__c": "0.0",
"type": "Lead",
"pi__first_search_type__c": null,
"Project_Amount__c": null,
"Report_Create_Month__c": "None",
"pi__Needs_Score_Synced__c": "false",
"Region__c": null,
"Marketing_Promo__c": null,
"Priority__c": "<img src=\"/servlet/servlet.ImageServer?id=0154W00000C2CLK&oid=00D4W000002SPDs\" alt=\" \" style=\"height:22px; width:22px;\" border=\"0\"/>",
"pi__created_date__c": null,
"pi__conversion_object_name__c": null,
"Street": null,
"escore__c": null,
"Product__c": null,
"PhotoUrl": null,
"Date_Converted__c": null,
"Deal_Approved_Date__c": null,
"State__c": null,
"Status": "New",
"Know_Decision_Maker__c": "false",
"IsDeleted": "false",
"Last_Modified_days__c": "0.0",
"pi__comments__c": null,
"Address_Mapped__c": "<a href=\"http://maps.google.com?q=%20%20%20\" target=\"_blank\"><img src=\"/servlet/servlet.FileDownload?file=0154W00000C2CKu\" alt=\"Map Address in Google\" border=\"0\"/></a>",
"Longitude": null,
"ConvertedDate__c": null,
"Days_Since_Last_Activity__c": null,
"GeocodeAccuracy": null,
"SIC_Code_Data__c": null,
"Competition__c": null,
"Ticker_Symbol__c": null,
"Country": null,
"Created_Date_without_Time__c": "2020-10-27",
"Id": "00Q4W00001ObjSiUAJ",
"Date_of_Last_Activity__c": null,
"Delinquency_Risk_Data__c": null,
"AnnualRevenue": null,
"Jigsaw": null,
"pi__utm_medium__c": null,
"Reported_Convert_Date__c": null,
"Description": null,
"ConvertedDate": null,
"DoNotCall": "false",
"NAICS_Code_Data__c": null,
"et4ae5__Mobile_Country_Code__c": null,
"Website": null,
"NumberOfEmployees": null,
"Salutation": null,
"Business_Family_Members_Data__c": null,
"pi__last_activity__c": null,
"Lead_Number__c": "000947",
"Scan_Image_URL__c": null,
"MSA_Data__c": null,
"partdir_mp__AC_Partner_Account__c": null,
"OwnerId": "0054W000008EssEQAS",
"Has_Budget__c": "false",
"RecordTypeId": "0124W000001FCtPQAW",
"ConnectionReceivedId": null,
"pi__conversion_object_type__c": null,
"analyticsdemo_batch_id__c": null,
"Source__c": "<img src=\"/servlet/servlet.ImageServer?id=0154W00000C2CLL&oid=00D4W000002SPDs\" alt=\" \" style=\"height:22px; width:22px;\" border=\"0\"/>",
"MayEdit": "true",
"EmailBouncedReason": null,
"Score1__c": "0.0",
"pi__grade__c": null,
"FirstName": "Max",
"Lead_Score_Value__c": null,
"IsLocked": "false",
"Accepted__c": "false",
"SystemModstamp": "2020-10-27T16:51:01.000Z",
"Lead_Rank__c": "Low",
"RatingColor__c": "color:blue",
"pi__score__c": null,
"Converted_Month__c": "None",
"LastActivityDate": null,
"pi__utm_content__c": null,
"Discovery_Explanation__c": "-12.909 because Trade Show Invite is false\n-21.619 because of other factors\nfrom the baseline, +77.763",
"LastTransferDate": "2020-10-27",
"pi__first_search_term__c": null,
"Disqual_Reason__c": null,
"Company": "MuleSoft",
"Email": null,
"Roof_Type__c": "Unknown",
"External_ID__c": null,
"Latitude": null,
"pi__campaign__c": null,
"pi__first_touch_url__c": null,
"MobilePhone": null,
"Add_to_Nurture_Campaign__c": "false",
"Name": "Max Mule",
"Industry": null,
"Twitter_Persona_ID__c": null,
"CreatedById": "0054W000008EssEQAS",
"pi__utm_campaign__c": null,
"Longitude__c": null,
"Lead_Score__c": "0 <img src=\"/servlet/servlet.FileDownload?file=0154W00000C2CLK&oid=00D4W000002SPDs\" alt=\"Red\" border=\"0\"/>",
"Top_Predictive_Result_1__c": null,
"pi__utm_source__c": null,
"ConvertedOpportunityId": null,
"MasterRecordId": null,
"IndividualId": null,
"Reported_Converted__c": "None",
"Lead_Age__c": "0.0",
"ConvertedAccountId": null,
"Facebook_Persona_ID__c": null,
"IsConverted": "false",
"HasOptedOutOfEmail": "false",
"LastViewedDate": "2020-10-27T16:51:01.000Z",
"Lead_Total__c": "0.0",
"DB_Days__c": null,
"Score3__c": "0.0",
"SIC_Description_Data__c": null,
"City": null,
"EngagementScoreId": null,
"Discovery_Outcome2__c": "43.236",
"Lead_Age_days__c": "0.0",
"Scan_Image__c": "<img src=\" \" alt=\"image\" style=\"height:200px; width:300px;\" border=\"0\"/>",
"Lead_Quality__c": "<img src=\"/servlet/servlet.FileDownload?file=0154W00000C2CL4\" alt=\" \" style=\"height:24px; width:22px;\" border=\"0\"/><img src=\"/servlet/servlet.FileDownload?file=0154W00000C2CL4\" alt=\" \" style=\"height:24px; width:22px;\" border=\"0\"/><img src=\"/servlet/servlet.FileDownload?file=0154W00000C2CL4\" alt=\" \" style=\"height:24px; width:22px;\" border=\"0\"/><img src=\"/servlet/servlet.FileDownload?file=0154W00000C2CL4\" alt=\" \" style=\"height:24px; width:22px;\" border=\"0\"/>",
"pi__first_activity__c": null,
"Product_Interest__c": null,
"CreatedDate__c": null,
"LeadSource": null,
"State": null,
"Latitude__c": null,
"CreatedDate": "2020-10-27T16:50:59.000Z",
"LastName": "Mule",
"EmailBouncedDate": null,
"Reported_Create_Month_del__c": null,
"Score2__c": "0.0",
"Rating": null,
"PostalCode": null,
"LastReferencedDate": "2020-10-27T16:51:01.000Z",
"PartnerAccountId": null,
"ScoreIntelligenceId": null,
"URLsrc__c": null,
"pi__notes__c": null,
"Project_Budget_Amount__c": null,
"ConnectionSentId": null,
"ConvertedContactId": null,
"et4ae5__HasOptedOutOfMobile__c": "false",
"Indicator_1_Positive__c": "false",
"Phone": null,
"Days_Remaining__c": null,
"maps__AssignmentRule__c": null,
"RoundRobin__c": "Target Campaign",
"Approval_Status__c": null,
"pi__url__c": null,
"Discovery_Outcome__c": null,
"SlickSidebar_Tab_Name__c": "Max Mule",
"IsUnreadByOwner": "false",
"Title": null,
"pi__Pardot_Last_Scored_At__c": null,
"pi__utm_term__c": null,
"Shadow_Roof_Type__c": null,
"Create_Month__c": "October",
"Decision_Timeframe__c": null,
"Registration_Expiration__c": null,
"NAICS_Description_Data__c": null,
"pi__conversion_date__c": null,
"Project_Defined__c": "false",
"pi__pardot_hard_bounced__c": "false",
"Fax": null,
"Data_com_Lead__c": "false",
"LastModifiedById": "0054W000008EssEQAS",
"JigsawContactId": null
}
}
Conclusion
As you can see from the above example, backing up data from Salesforce to S3 is a simple process using the Amazon S3 Connector. Using Dataweave, you can iterate through an existing object on S3, and add new data to that object. When you are done transforming the payload, use the Create Object S3 Connector to upload the modified file back to S3.
The example shown in this tutorial is only scratching the surface of the potential integrations you can develop using the Amazon S3 Connector. There are many instances where you will need to back up large files from Salesforce to S3 since Salesforce can only support a maximum file size of 25mb.
The S3 Connector also allows you to listen for when a new object is created in your bucket using the On New Object Connector. For instance, you could listen for a new object to be uploaded, then modify that object in your flow and reupload it to S3.
The possibilities are truly endless with the Amazon S3 Connector. To learn more about MuleSoft and to read more tutorials, please visit the developer tutorials homepage.



Try Anypoint Platform for free
Start your 30-day free trial of the #1 platform for integration, APIs, and automation. No credit card required. No software to install.
Questions? Ask an expert.